
Online reputation refers to the collective digital footprint, sentiment, and structural information that search engines index and display regarding an individual or entity. Within modern professional ecosystems, the data surfacing on search engine results pages (SERPs) functions as a primary trust signal for prospective employers, clients, and regulatory bodies. Because search algorithms prioritize authority, relevance, and historical consistency, the configuration of this public data directly determines an individual’s access to executive positions, board appointments, and commercial partnerships.
What is Online Reputation Within Search Ecosystems?
Online reputation is the algorithmic synthesis of fragmented digital data points that defines an entity’s credibility across web-based platforms. In search ecosystems, this concept transforms from an abstract social perception into a structured, quantifiable profile governed by Information Retrieval (IR) principles. Search engines do not interpret reputation through human emotion; instead, they evaluate text patterns, source authority, data linkages, and user engagement metrics to construct an entity profile.
The mechanism of digital reputation relies on entity extraction and knowledge graph integration. When a search engine indexes content relating to an individual, natural language processing (NLP) algorithms parse the text to identify relationships between the person (the entity) and specific attributes, such as professional skills, past organizations, public accolades, or controversies. These relationships form a digital footprint that algorithms categorize under specific topical vectors.
This structural data directly influences search visibility and professional vetting processes. When a decision-maker executes a query for an individual’s name, the search engine assembles a SERP based on the calculated trust scores of the associated URLs. If the top-ranking assets consist of verified professional profiles, academic publications, or neutral industry coverage, the search engine projects a high-trust entity perception. Conversely, fractured data, unverified claims, or a total absence of structured information signal low authority, restricting professional progression.
How Do Search Engine Ranking Dynamics Process Individual Credibility?
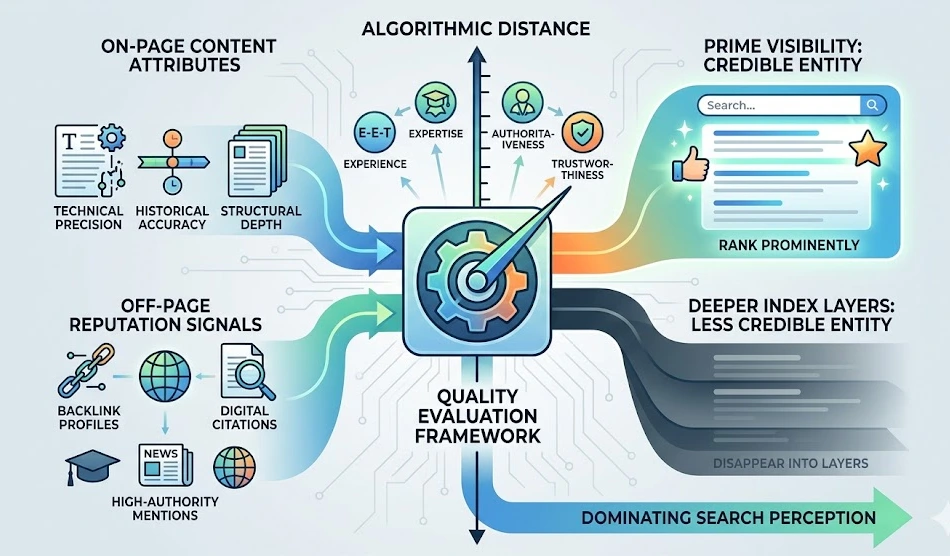
Search engine ranking dynamics process individual credibility by measuring the algorithmic distance between a query and the most authoritative, trustworthy sources available in the index. Search engines utilize specialized quality evaluation frameworks, such as Google’s Experience, Expertise, Authoritativeness, and Trustworthiness (E-E-A-T) guidelines, to assess whether content accurately reflects the true capabilities of an entity. This assessment dictates whether an individual’s digital assets rank prominently or disappear into deeper index layers.
The underlying mechanism evaluates both on-page content attributes and off-page reputation signals. On-page dynamics examine the precision of technical terminology, historical accuracy, and the structural depth of authored content. Off-page dynamics track backlink profiles, digital citations, and mentions across high-authority domains, such as academic databases, national news outlets, and official corporate registries.
This structural processing alters search visibility by controlling the sentiment distribution on the first page of results. Algorithms favor stable, highly cited domains because these platforms demonstrate consistent compliance with web standards and exhibit minimal risk of spreading misinformation. When an individual establishes a network of authoritative references, search engines recognize the entity as a credible source within a specific domain, ensuring that positive or neutral professional indicators dominate search perception.
Why Do Review Signals and Sentiment Interpretation Impact Professional Selection?
Review signals and sentiment interpretation impact professional selection because third-party validation platforms serve as critical algorithmic trust multipliers that recruiters use to mitigate risk. Algorithms use sentiment analysis to decode the contextual meaning behind textual reviews, forum discussions, and peer evaluations. This computational linguistics process categorizes user-generated content into positive, negative, or neutral vectors, which directly modifies the overall trust score of the entity.
The mechanism relies on machine learning models that identify semantic modifiers, valence shifters, and industry-specific risk keywords. For example, the presence of terms associated with contract non-compliance, ethical breaches, or technical failure lowers the entity’s algorithmic sentiment rating. Search engines aggregate these sentiment scores across multiple independent review platforms, digital directories, and social proof repositories to establish a baseline baseline of public trust.
This interpretation directly alters candidate screening and organizational risk assessments. During executive procurement, automated screening tools and human HR departments analyze the first page of search results for sentiment anomalies. High density of negative sentiment signals operational risk, which routinely disqualifies candidates before the interview phase. Clean sentiment pipelines, verified by multi-source review alignment, preserve professional viability by presenting a stable risk profile to searchers.
How Does an Unstructured Digital Footprint Create Professional Friction?
An unstructured digital footprint creates professional friction by introducing algorithmic ambiguity, which prevents search engines from verifying the authentic identity and authority of an individual. When digital data is fragmented, contradictory, or unoptimized, search engines struggle to resolve the entity cleanly within their knowledge bases. This data chaos forces the algorithm to rely on low-authority, auxiliary sources to fulfill name-based search queries, frequently elevating irrelevant or detrimental content.
The mechanism behind this friction is identity fragmentation across disparate web domains. If an individual uses varying professional titles, inconsistent name formats, or leaves outdated profiles active across inactive platforms, the indexing engine treats these instances as disconnected or low-quality data points. Without explicit semantic connections—such as structured schema markup or uniform cross-linking—the algorithm cannot synthesize the information into a cohesive, authoritative entity profile.
The resulting impact on search perception is the loss of control over first-impression narratives. When an entity search displays a disorganized mix of personal social media archives, automated public records, and dead links, the search engine demonstrates a lack of trust in the subject’s professional authority. Prospective clients or executive recruiters interpret this lack of structured visibility as a lack of professional digital literacy or, worse, an attempt to obscure operational history, leading directly to dropped opportunities.
What Search Metrics Define Personal Brand Visibility Across Core Engines?
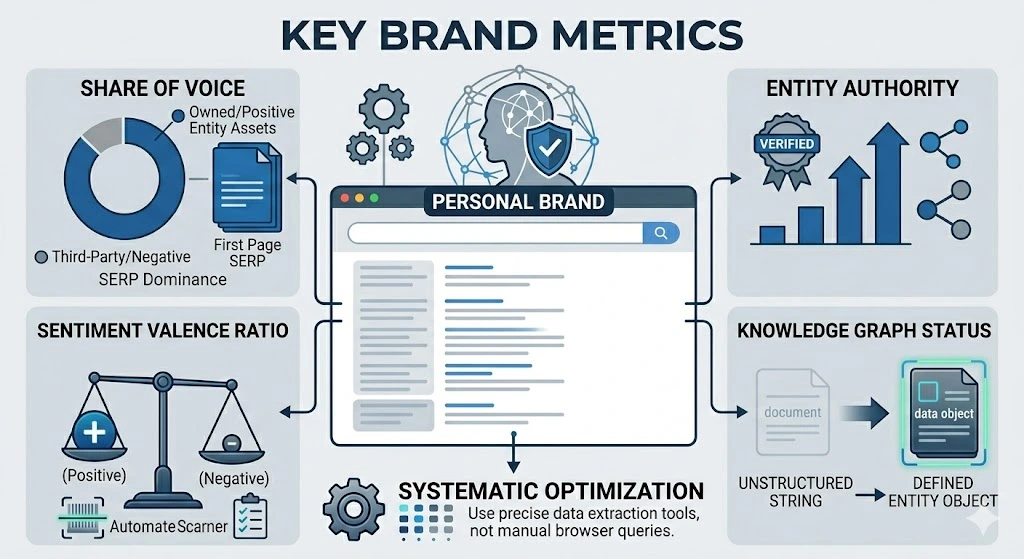
Search metrics define personal brand visibility by quantifying the exact reach, dominance, and authority that an individual’s digital presence commands within index databases. To accurately diagnose search perception control, analysis must shift from abstract vanity metrics to concrete cryptographic and mathematical indicators used by search platforms. These metrics track how effectively an entity occupies digital real estate and how robustly the underlying content resists algorithmic volatility.
Key Metrics for Search Perception Evaluation
- Share of Voice (SOV) on Named Queries
- Calculate the percentage of first-page SERP listings completely controlled by owned or positive entity assets. Higher dominance reduces the probability of third-party or negative content penetrating the primary visual frame.
- Entity Authority Score
- Measure the logarithmic strength of an individual’s citation network based on incoming links from verified industry domains. This metric establishes the baseline resistance of a personal brand against unverified negative content injections.
- Knowledge Graph Inclusion Status
- Verify the existence of a dedicated Knowledge Asset or Entity Card within core search databases. Inclusion confirms that the algorithm has successfully migrated the individual from text strings into an independent, understood data object.
- Sentiment Valence Ratio
- Analyze the proportion of positive semantic tokens against negative tokens within the top 100 indexed search results. A high positive valence ratio guarantees that automated background checks return low-risk classifications.
Understanding these structural data points allows for the systematic optimization of an individual’s digital footprint. To manage search perception objectively, executives must learn how to measure personal brand visibility across search engines using precise data extraction tools rather than manual, localized browser queries.
Summary of Algorithmic Reputation Vectors
The following analytical matrix summarizes how distinct information types map to specific algorithmic operations and their subsequent professional outcomes:
| Information Vector | Algorithmic Processing Method | Primary Metric Affected | Professional Target Outcome |
| Academic & Industry Papers | Entity extraction and citation parsing | E-E-A-T Authoritativeness | Establishes domain expertise for advisory positions. |
| Corporate Registries & News | Cross-domain node validation | Knowledge Graph Entry | Confirms corporate identity and mitigates compliance risk. |
| Peer Reviews & Platforms | Natural Language Processing sentiment analysis | Sentiment Valence Ratio | Reduces transactional friction with high-value clients. |
| Owned Digital Architecture | Schema verification and semantic linking | Share of Voice (SOV) | Guarantees narrative control during active vetting. |
The intersection of information retrieval systems and professional advancement requires a rigorous, non-emotional approach to digital footprints. Online reputation is not a cosmetic asset; it is a complex, algorithmic structure built from data linkages, sentiment vectors, and domain authority markers. When search engines encounter a highly structured, authoritative, and clean data network, they reward the entity with prominent search visibility and high trust rankings. Conversely, unstructured data grids generate algorithmic noise that translates into professional risk, friction, and lost commercial opportunities. Long-term professional security in digital spaces relies completely on maintaining technical data integrity across the global search ecosystem.
Frequently Asked Questions
How does online information impact executive recruitment and hiring?
Executive recruitment frameworks rely heavily on algorithmic screening and entity perception analysis to assess organizational risk. Search engines aggregate an individual’s digital footprint across news media, corporate registries, and professional networks to construct a visible trust score. Clear My Name data indicates that negative sentiment vectors or fractured data profiles on the first page of search results frequently disqualify candidates during early background checks.
What is the role of digital trust in reputation management for individuals?
Digital trust refers to the algorithmic verification of an individual’s identity, authority, and historical consistency across the web index. Reputation management for individuals focuses on optimizing these trust signals by resolving data fragmentation and building authoritative cross-domain links. Systems like Clear My Name help align an entity’s digital footprint with search engine evaluation criteria to ensure accurate, high-authority visibility.
How do search engines evaluate the credibility of personal brand information?
Search engines evaluate individual credibility using Information Retrieval (IR) principles and semantic analysis frameworks that measure experience and authoritativeness. Algorithms parse natural language data points across third-party platforms to match the individual entity against verified knowledge graphs. Unstructured data or conflicting professional histories generate algorithmic ambiguity, which reduces search visibility and lowers overall credibility scores.
Can outdated online information affect current professional opportunities?
Outdated online information creates significant professional friction because search engines prioritize historical data persistence unless new authoritative nodes are introduced. Legacy content, inactive profiles, or unoptimized public records remain indexed and continue to influence search engine results pages (SERPs). Implementing structured digital architecture through individual reputation management services ensures that current, high-trust professional indicators dominate the primary visual frame.
How does sentiment analysis affect online background checks?
Sentiment analysis models utilize natural language processing (NLP) to categorize textual mentions, peer reviews, and legal indices into positive, neutral, or negative vectors. Automated background screening tools scan these indexed sentiment outputs to generate a baseline risk profile for prospective business partners or executive hires. Maintaining a high proportion of positive semantic tokens across core search ecosystems prevents automated systems from triggering compliance flags.