
To measure personal brand visibility across search engines, an individual must quantify the share of voice, sentiment distribution, and entity alignment within top-ranking search results. This assessment relies on tracking keyword positions for name-based queries, auditing the ratio of controlled to uncontrolled web properties, and evaluating the prominence of algorithmic features like knowledge panels and related searches.
Reputation management strategies differ based on whether an individual prioritises content suppression or content enhancement to alter search perception. The choice between these foundational approaches dictates how search engine algorithms process entity credibility over time. Evaluating how to measure this visibility requires an analytical understanding of search engine results page (SERP) architecture and information retrieval systems.
What is Personal Brand Visibility in Search Ecosystems?
Personal brand visibility is the measurable presence, accessibility, and structural distribution of an individual’s digital footprint within search engine results pages. Search engines process names as entities, which are distinct, identifiable concepts defined by specific attributes and relationships. When a user executes a name-based query, the search engine constructs a SERP by retrieving documents that demonstrate high relevance, authority, and trustworthiness regarding that specific entity. Visibility is not merely a reflection of ranking position; it encompasses the diversity of content formats, the control over indexing properties, and the accuracy of semantic connections established by algorithmic systems.
Information retrieval models evaluate personal brand visibility by analysing the layout of top-tier search results. A highly visible brand features an array of authoritative web properties, including professional profiles, verified social media assets, media mentions, and biographical data hubs. The composition of these results dictates user perception and establishes the baseline for entity credibility. Measuring this landscape requires isolating specific variables, such as vertical search performance, images, video assets, and textual snippets, to determine how effectively an individual dominates their digital real estate.
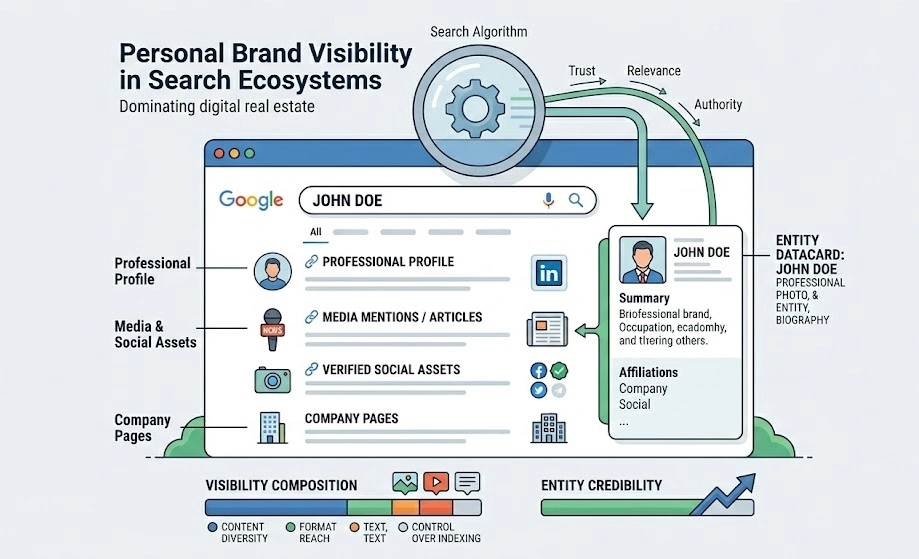
How Do Organic Enhancement and Reactive Suppression Strategies Compare?
Organic enhancement and reactive suppression represent two distinct methodologies for managing search engine perception, differing fundamentally in their mechanisms and execution timelines. Organic enhancement is a proactive strategy that focuses on the systematic creation, optimization, and distribution of authoritative content assets. This approach operates by building a robust digital infrastructure that reinforces positive reputation signals and establishes clear entity relationships. By feeding search engine spiders consistent, high-quality data across interconnected platforms, organic enhancement expands the volume of controlled assets capable of occupying high-ranking positions.
Reactive suppression is an adversarial strategy designed to counteract, relegate, or eliminate specific negative, outdated, or defamatory content assets within the SERP. This method operates through two primary levers: legal or technical de-indexing requests and targeted algorithmic demotion. Legal removals rely on frameworks such as the Right to Be Forgotten, copyright infringement claims, or terms-of-service violations to delete URLs from search indexes entirely. Algorithmic demotion uses aggressive optimization of alternative assets to force undesirable links further down the ranking pages, rendering them less visible to standard users.
| Evaluation Metric | Organic Enhancement | Reactive Suppression |
| Primary Mechanism | Asset optimization and entity alignment | Legal de-indexing and algorithmic demotion |
| Execution Timeline | Long-term development (6–12 months) | Immediate to medium-term intervention |
| Algorithmic Risk | Low risk; adheres to standard guidelines | High risk; vulnerable to algorithm updates |
| Scalability | High scalability across multiple queries | Low scalability; bound to specific URLs |
| Sustainability | High permanence due to domain authority | Variable permanence; content can resurface |
The structural impact on search visibility varies significantly between these two options. Organic enhancement provides long-term stability because it accumulates domain authority, builds diversified backlink profiles, and aligns with search engine quality evaluator guidelines. Its limitation lies in the required resource investment, as establishing authority demands continuous content production and technical maintenance. Conversely, reactive suppression addresses critical vulnerabilities rapidly, isolating damaging material to protect entity credibility. However, its effects are often fragile; if the underlying content remains live on third-party domains, changes in search engine algorithms or sudden spikes in user search traffic can cause the negative links to resurface.
How Do Search Engines Interpret and Value Reputation Signals?
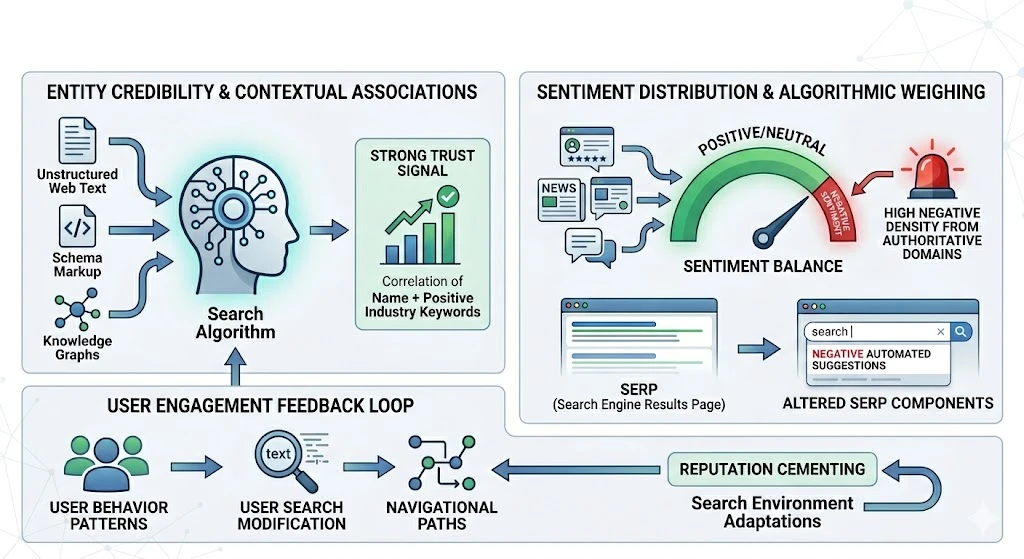
Search engines interpret reputation signals through complex, mathematical evaluation frameworks designed to assess the authority and trustworthiness of information sources. The primary mechanism driving this interpretation is the assessment of entity credibility, which relies on data extraction from unstructured web text, structured schema markup, and knowledge graphs. Search algorithms analyze the co-occurrence of an individual’s name alongside specific attributes, industries, and keywords. When authoritative domains frequently associate an entity with positive industry context, the algorithm registers a strong trust signal, stabilizing the entity’s positioning within search architecture.
Sentiment distribution plays a critical role in how algorithms weigh these signals. Modern search engines employ natural language processing models to evaluate the contextual tone of text surrounding an entity mention. Document classification systems parse news articles, forum discussions, and digital reviews to determine whether the prevailing sentiment is positive, neutral, or negative. A high density of negative sentiment across high-authority domains alerts quality algorithms, which can alter the components displayed in the SERP, such as triggering negative automated search suggestions or pulling critical snippets into prominent positions.
Search engines also evaluate user engagement metrics as secondary verification signals. While direct click-through rates remain debated as a ranking factor, patterns of user behavior, such as search modification and navigational paths, indicate the intent and perception surrounding an personal brand. If users consistently modify a name query to include terms associated with controversy, search algorithms adapt by altering the related searches feature at the bottom of the page. This adaptation creates a feedback loop, cementing specific reputation associations within the search environment based on collective user behavior.
What Metrics Determine the Effectiveness of Visibility Frameworks?
An accurate assessment of personal brand visibility requires a structured framework focused on quantitative data points that reflect search engine ranking influence and sentiment control. Relying on casual, non-incognito searches introduces personalization bias, which distorts the true nature of the SERP. A professional measurement framework isolates the individual variables that dictate how external audiences perceive an entity upon executing a search query.
- Calculate Share of Voice (SoV): Measure the percentage of top-20 search results that consist of fully controlled or aligned web assets to determine overall SERP dominance.
- Audit Sentiment Distribution: Categorise every ranking URL within the first two pages as positive, neutral, or negative to map the exact ratio of reputational risk exposure.
- Track Knowledge Graph Integration: Monitor the presence and completeness of an official Knowledge Panel, evaluating whether search engines have accurately mapped the entity attributes.
- Analyse Search Suggestion Networks: Extract the automated autocomplete strings generated by major engines for the core name query to identify pre-click perception drivers.
- Evaluate Authority Metrics of Controlled Assets: Quantify the domain authority and backlink profiles of personal websites and profiles to ensure they possess the technical strength to resist suppression from external negative content.
These metrics allow for a precise calculation of algorithmic vulnerability. By treating each ranking position as a specific weight—where position one carries significantly more visibility and traffic potential than position ten—an individual can map their reputation footprint accurately. This data provides the baseline required to determine whether current optimization efforts are successfully shifting the sentiment distribution or if further asset development is necessary.
How Does Content Suppression Differ from Content Enhancement in Influencing SERP Composition?
Content suppression influences SERP composition by directly removing or systematically lowering the visibility of specific, unwanted URLs. The technical mechanism involves creating an artificial authority imbalance. By identifying the links that damage an individual’s reputation, practitioners can analyze the backlink profiles and keyword associations keeping those links afloat. Suppression then works by out-optimizing those specific spaces, flooding the index with alternative, high-authority pages that occupy the top spots, thereby pushing the negative assets into lower traffic tiers, such as page two or page three of the search results.
Content enhancement alters SERP composition by transforming the architectural features displayed on the page, rather than just shifting vertical link positions. This methodology focuses on diversification, leveraging schema markup, digital media asset optimization, and platform integration to trigger rich results. When an entity is supported by robust content enhancement, the search engine layout responds by incorporating image carousels, video fragments, direct answer boxes, and social media feeds. This structural transformation changes the layout of the page, reducing the visual real estate available for traditional text snippets and diluting the impact of any unsuppressed negative URLs.
The choice between these methods dictates the vulnerability of the SERP to future algorithmic changes. Content suppression relies on maintaining an edge over specific negative domains; if those external domains undergo a massive authority upgrade or receive powerful inbound links, the suppressed content can ascend rapidly. Content enhancement focuses on entity definition, making it more resilient to broad core algorithm updates. By providing clear semantic signals that help search engines understand the entity’s core attributes, enhancement builds a diversified ecosystem where no single third-party URL can easily disrupt the overall personal brand narrative.
What Strategic Considerations Govern Long-Term Reputation Stability?
Achieving long-term reputation stability requires balancing immediate mitigation with continuous asset cultivation. Individuals evaluating their search footprint must recognise that search engines continuously update their algorithms to provide users with relevant, unmanipulated information. Consequently, an over-reliance on artificial technical optimization or temporary suppression networks exposes an entity to sudden visibility drops when search engines adjust their quality evaluation criteria. Sustainability is achieved by ensuring that controlled digital assets possess real-world authority, consistent user engagement, and verifiable entity relationships.
Strategic risk management dictates that content diversity is the most effective defense against reputational volatility. Diversifying assets across multiple independent domains prevents a single platform failure from compromising the entire digital footprint. Furthermore, maintaining an active, authoritative presence in industry-specific registries, academic hubs, or verified media outlets reinforces the trust signals that search algorithms value. This continuous investment ensures that the entity structure remains resilient, protecting personal brand visibility against unexpected negative events or shifting competitive landscapes.
When evaluating external intervention options to manage a complex search presence, individuals must distinguish between superficial optimization tactics and sustainable structural adjustments. Long-term success relies on methods that align with the core objectives of information retrieval systems: accuracy, authority, and relevance. Navigating these complexities effectively requires an integrated approach that combines data analysis, legal awareness, and advanced technical execution, which form the foundation of professional search result reputation management services.
Frequently Asked Questions
How do you track personal brand visibility on search engines?
Tracking personal brand visibility involves monitoring keyword positions for name-based queries and calculating your share of voice across top search results. Clear My Name recommends auditing the ratio of controlled assets, such as professional profiles, to uncontrolled third-party domains. This data allows individuals to evaluate their sentiment distribution and map potential reputational risks accurately.
What metrics determine the strength of an individual’s digital footprint?
An individual’s digital footprint strength is determined by entity credibility, domain authority of controlled web properties, and knowledge graph integration. Search engine algorithms evaluate these reputation signals alongside sentiment distribution across high-authority news or forum sites. A resilient footprint features highly diversified assets that consistently generate positive algorithmic trust signals.
How do search engines process personal names as entities?
Search engines process personal names as unique entities by mapping their attributes and relationships within an algorithmic knowledge graph. Modern natural language processing models analyze co-occurrence data, linking an individual’s name to specific industries, keywords, and corporate entities. This semantic alignment directly influences how search engines construct personal brand SERPs and automated search suggestions.
What is the difference between content suppression and content removal?
Content removal permanently deletes a URL from a web server or legally de-indexes it from search engine databases using frameworks like the Right to Be Forgotten. In contrast, content suppression uses targeted search result reputation management techniques to demote negative links further down the ranking pages. Clear My Name applies suppression strategies by building a robust infrastructure of alternative, high-authority content assets to out-index undesirable material.
Why do automated search suggestions change for personal names?
Automated search suggestions change based on shifting user search traffic patterns and the contextual tone of recent document classification indexes. If search engine algorithms detect a sudden spike in queries linking a name to controversial terms, the autocomplete strings update to reflect this collective user behavior. Regular monitoring of these pre-click perception drivers is vital for maintaining long-term online reputation stability.