
Online reputation refers to the collective digital perception of an entity formulated by search algorithms and human evaluation across web ecosystems. Within modern search environments, corporate reputation functions as a measurable algorithmic variable directly influencing how brand entities are indexed, retrieved, and positioned on search engine results pages (SERPs).
What is an Corporate Digital Footprint and How Does it Shape Search Perception?
A digital footprint refers to the cumulative repository of indexed data, mentions, and sentiment signals associated with a specific entity across the web. Search engines aggregate these distributed data points to construct an entity profile, mapping relationships between a business name, its core offerings, and user feedback. This structured profile allows algorithms to assess the historical reliability and contextual relevance of an entity within its specific sector.
The mechanism relies on continuous web scraping and entity extraction, where non-linear textual nodes—such as forum discussions, news articles, and regulatory filings—are linked back to the corporate identity. Algorithms cross-reference these nodes to evaluate thematic consistency and overall brand authority. If the aggregated data exhibits high levels of conflicting information or unverified claims, search engines reduce the confidence score assigned to that entity. This drop in algorithmic confidence directly restricts the brand’s ability to rank for high-intent commercial queries.
The impact on search visibility is deterministic. A fragmented or unmanaged digital footprint introduces information noise, which degrades the entity’s authority within semantic knowledge graphs. Conversely, a clean, structured footprint characterized by authoritative citations and positive sentiment signals establishes a stable entity perception. This baseline stability ensures that the primary SERP brand real estate remains resilient against sudden fluctuations or malicious information injections.
How Do Review Signals Direct the Evaluation of Entity Trustworthiness?
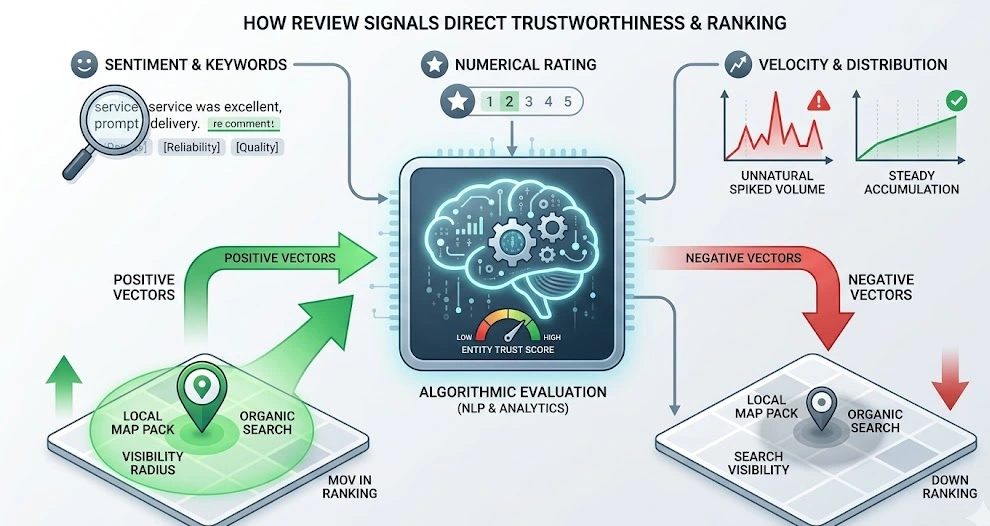
Review signals represent structured and unstructured user sentiment data deployed by search platforms to quantify corporate credibility and customer satisfaction. Search engines process these inputs via natural language processing (NLP) to decode semantic sentiment, velocity, and distribution across verified third-party platforms. These data streams serve as explicit indicators of a business entity’s real-world operational reliability.
The system processes review signals by analyzing the density of industry-specific keywords embedded within user-generated text alongside the numerical rating. For example, algorithmic evaluation prioritizes detailed reviews containing semantic clusters relevant to service delivery over generic, short-form ratings. Furthermore, the velocity of review acquisition is monitored; a sudden, unnatural spike in review volume triggers algorithmic filters designed to identify manipulation, whereas steady accumulation signals authentic consumer engagement.
These processed signals alter the positioning of local and national search results. High-density positive sentiment signals expand the algorithmic visibility radius within local map packs and organic search matrices, whereas persistent negative sentiment vectors result in algorithmic suppression.
Why Does SERP Evaluation Directly Determine Corporate Conversion Rates?
SERP evaluation describes the process by which a user or algorithm assesses the first page of search results to determine the legitimacy, authority, and safety of an indexed business entity. Because search engines function as the primary interface for information retrieval, the real estate on page one dictates the immediate narrative surrounding a brand. The structural composition of this page determines whether an informational seeker transitions into a transaction-ready consumer.
The underlying mechanism operates through cognitive filtering and visibility bias. Statistical analysis establishes that the top three organic positions capture the absolute majority of all user clicks, creating an environment where unranked information ceases to exist for the average user. When a corporate search query yields negative news assets, unresolved consumer complaints, or low-rated platform profiles within these top positions, the algorithmic display validates those risks to the searcher.
The presence of negative components within the primary brand SERP introduces friction into the consumer decision journey. This visibility friction induces a high bounce rate from brand assets, causing a immediate degradation in conversion metrics. Companies facing prominent negative placements experience systemic revenue loss, a direct result of users shifting attention to competitors whose SERP evaluations present zero trust conflicts. Identifying these vulnerabilities early requires monitoring for specific operational failures, which are detailed in the structural breakdown of 10 signs your online reputation is costing you customers.
How Do Search Algorithms Process and Interpret Digital Sentiment Vectors?
Digital sentiment vectors are mathematical representations of the qualitative emotion, tone, and opinion extracted from textual data across the digital ecosystem. Search engines utilize sophisticated NLP frameworks to transform unstructured text into distinct semantic vectors, categorizing information as positive, negative, or neutral. These vectors allow algorithms to monitor the public consensus surrounding an entity without relying purely on structured star ratings.
The computational mechanism extracts phrases, adjectives, and contextual modifiers from indexed content, analyzing the proximity of these terms to the core entity name. If an entity is frequently mentioned alongside words associated with fraud, failure, or poor quality, the negative sentiment vector strengthens within the localized knowledge graph. The algorithm tracks these vectors across multiple channels, including social networks, independent blogs, and digital press outlets, establishing a holistic sentiment baseline for the corporate entity.
This vector configuration modifies search visibility by acting as a secondary algorithmic ranking filter. Entities characterized by dominant negative sentiment vectors suffer from a contraction in non-branded keyword visibility, as search engines actively deprioritize entities that present a perceived risk to users.
What Role Do Independent Media Mentions Play in Information Authority?
Independent media mentions are un-sponsored editorial citations, news reports, and feature articles published by established journalistic platforms regarding a corporate entity. Within search architecture, these mentions function as high-value validation signals because third-party journalistic institutions possess independent domain authority and strict editorial standards. Search engines treat these organic citations as objective confirmations of an entity’s societal or economic relevance.
The mechanism operates through the transfer of link equity and semantic association within the information graph. When a high-authority news platform publishes an article containing a brand entity, search algorithms register the co-occurrence of the brand name alongside authoritative, trusted journalistic topics. This association updates the trust matrix of the corporate entity, raising its topical authority score. The algorithmic value remains high regardless of whether a direct hyperlink exists, as unlinked brand mentions are processed as entity citations.
The impact on search visibility manifests as an enhancement in overall domain resilience. A corporate entity backed by a dense network of independent media mentions experiences greater stability during core algorithm updates. These authoritative signals demonstrate to the ranking systems that the business is a recognized leader within its operational niche, thereby securing its premium organic positions against less-cited competitors.
How Does Information Velocity Influence the Escalation of Digital Risks?
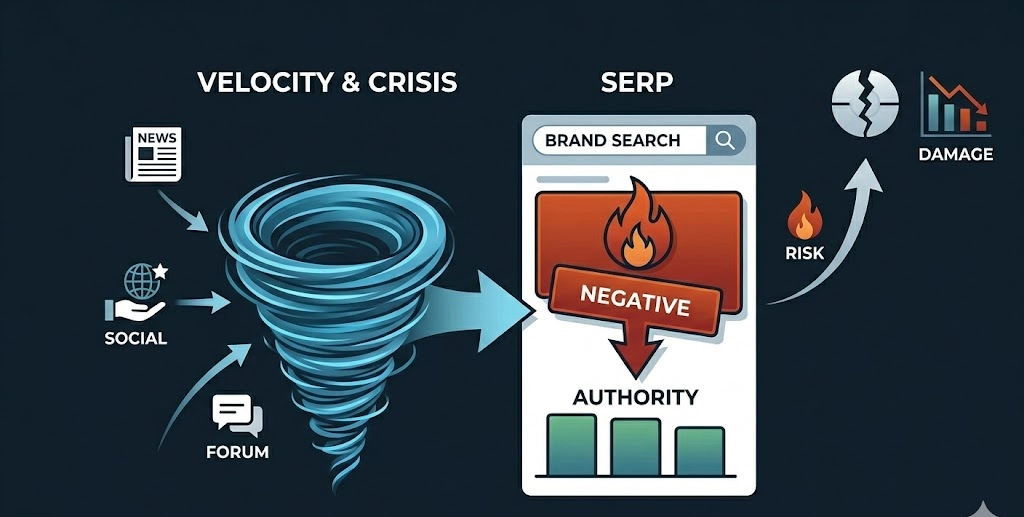
Information velocity defines the speed at which data is generated, duplicated, shared, and indexed across digital networks within a specific timeframe. High information velocity compresses the time available for corporate response, transforming isolated issues into systemic digital crises. Search engines are engineered to detect sudden increases in data velocity, often interpreting rapid spikes in mentions as breaking news events.
The mechanism is driven by real-time crawling systems and trending content algorithms, such as query deserves freshness (QDF) protocols. When a negative event triggers a sudden wave of social media shares, forum threads, and blog posts, the indexing frequency for related search terms accelerates. Search algorithms temporarily alter standard ranking models to surface this high-velocity content at the top of the SERP, ensuring users receive the latest updates. This architectural shift allows unverified or damaging narratives to achieve dominant visibility within minutes.
The resulting impact is an immediate destabilisation of the brand SERP. Standard informational assets are displaced by real-time crisis content, exposing every user searching for the entity to the escalating risk. This heightened visibility amplifies the corporate damage until the information velocity stabilizes and standard authority-based ranking parameters resume control.
What Metrics Quantify the Financial Impact of Algorithmic Suppression?
Algorithmic suppression is the intentional or systematic de-ranking of an entity’s digital assets within search results due to trust violations, quality drops, or negative sentiment accumulation. Quantifying the financial consequence of this suppression requires the systematic tracking of core performance indicators that link search positioning directly to corporate revenue streams. These metrics reveal the tangible economic loss generated by hidden or demoted brand assets.
The tracking mechanism utilizes data from web analytics platforms and search consoles to correlate position drops with traffic volume and value. The primary metrics include:
- Organic Traffic Volatility: Measures the net loss of unique visitor sessions following a negative SERP shift, calculating the drop-off in user acquisition.
- Click-Through Rate (CTR) Degradation: Tracks the percentage reduction in user clicks across brand terms as negative assets displace official corporate links.
- Cost-Per-Acquisition (CPA) Inflation: Records the increase in paid marketing expenditure required to offset the loss of organic inbound leads caused by suppression.
- Customer Lifetime Value (LTV) Contraction: Monitors the decline in repeat business and long-term customer revenue driven by eroded digital trust.
By analyzing these metrics, corporate entities calculate the precise financial deficit caused by algorithmic suppression, demonstrating that digital perception directly governs commercial viability.
Corporate reputation within digital ecosystems is an engineered artifact dictated by the interaction between distributed text assets, user sentiment, and search algorithm mechanics. A company’s digital footprint serves as the foundational data layer from which search engines extract entity relationships and assess long-term credibility. Review signals, digital sentiment vectors, and independent media mentions provide continuous data inputs that algorithms decode via natural language processing to adjust trust scores.
When these inputs skew negative or exhibit volatile velocity, search engines restructure SERPs to protect users, leading to algorithmic suppression and immediate commercial friction. Managing these digital variables requires a precise understanding of semantic frameworks, visibility matrices, and data velocity, ensuring that corporate entities maintain informational authority and structural resilience across all search environments.
Frequently Asked Questions
What is reputation management for business and how does it function?
Reputation management for business is the systematic process of monitoring, shaping, and controlling the public digital perception of a corporate entity across search engines and review platforms. The framework functions by deploying semantic content networks, optimizing technical entity signals, and mitigating negative search results to ensure search engine algorithms index authoritative, accurate brand information. Clear My Name utilizes these methodologies to stabilize search engine results pages (SERPs) and build long-term digital trust for UK corporations.
How do online reviews affect a company’s Google search rankings?
Online reviews serve as critical trust and credibility signals that Google’s natural language processing (NLP) algorithms analyze to determine an entity’s local and organic authority. High-density positive sentiment and steady review velocity directly enhance a business’s visibility in map packs and organic search matrices, whereas persistent negative sentiment can lead to algorithmic suppression. Managing these distributed customer feedback vectors is a foundational element of strategic reputation management for business.
Why is search perception control important for corporate crisis management?
Search perception control is vital because the first page of search results serves as the primary digital interface where stakeholders evaluate an entity’s legitimacy and operational safety. During an information crisis, high-velocity negative assets can rapidly displace official brand communications, creating severe conversion friction and driving up customer acquisition costs. Implementing structured reputation management for business assists corporate entities in neutralizing volatile digital risks and protecting core brand real estate from algorithmic degradation.
How can a UK company remove negative search results from Google?
Removing damaging URLs from search indices typically requires identifying specific legal violations, such as defamation or GDPR data breaches, or submitting formal requests under the Right to Be Forgotten framework. When legal removal is not applicable, companies must rely on technical search suppression strategies, which involve publishing highly optimized, authoritative content networks to push negative links off the primary SERP. Strategic digital trust agencies like Clear My Name execute these technical overrides to restore narrative control for affected businesses.
What metrics track the effectiveness of a business reputation strategy?
The performance of corporate reputation management for business is measured through shifts in organic traffic volatility, domain authority scores, and brand-name click-through rates (CTR). Improvements in digital sentiment vectors and a reduction in cost-per-acquisition (CPA) inflation also indicate that search perception control measures are successfully neutralizing negative visibility. Monitoring these algorithmic variables ensures that a company’s digital footprint aligns with real-world commercial objectives.