Reputation management strategies differ based on how search engines process entity data and how voters evaluate digital signals during election cycles. Online reputation control methods are evaluated through their capacity to modify sentiment distribution, establish entity authority, and withstand algorithmic updates across search engine results pages (SERPs).
Which Digital Reputation Signals Directly Influence Voter Perception?
Search engines interpret political figures as unique entities within a knowledge graph, mapping relationships between the individual, policy positions, and public sentiment. Voter perception relies heavily on the immediate sentiment distribution of the first page of search results, where unverified claims often carry the same visual weight as authoritative journalistic reporting. When a voter queries a candidate’s name, the algorithmic retrieval system prioritises relevance, freshness, and source authority. If the top-ranking documents contain algorithmic trust violations, such as uncorrected historical errors or dense clusters of negative press, the entity’s baseline credibility drops.
The mechanism driving this processing relies on entity attributes. Search algorithms cross-reference a politician’s name with specific digital footprints, evaluating the historical consistency of information across multiple high-authority domains. Content suppression and content enhancement represent the two primary structural mechanisms used to alter this footprint. Content suppression operates by down-ranking negative assets through the promotion of neutral or positive documents, whereas content enhancement focuses on publishing highly optimised, fact-based resources to saturate the SERP proactively.
| Evaluation Metric | Organic Content Enhancement | Reactive Content Suppression |
| Search Ranking Influence | High long-term stability via authority building | Variable short-term impact via link dilution |
| Entity Credibility | Establishes verified primary data sources | Masks immediate risks without fixing root data |
| Sentiment Distribution | Creates balanced, diverse information networks | Shifts negative links to lower search positions |
| Algorithmic Sustainability | High resilience against core search updates | Vulnerable to structural algorithm adjustments |
Organic alignment with algorithmic trust factors yields sustainable search visibility. Reactive adjustments, while necessary during active crises, fail to build the underlying entity authority required to survive sustained negative search volume.
How Do Proactive Content Networks Compare to Reactive Crisis Management?
Proactive content networks focus on the strategic creation of an interconnected web of digital assets before an informational vulnerability emerges. This method operates by establishing absolute ownership over branded search terms through official profiles, policy whitepapers, and verified digital entities. The mechanism relies on saturation; by occupying the top organic positions with controlled, high-authority domains, the candidate reduces the available real estate for negative or unverified content. The structural limitation of this approach is the resource investment required to maintain topical authority across multiple distinct channels simultaneously.
Reactive crisis management relies on rapid content deployment and technical search engine optimization (SEO) tactics to counter an immediate surge in negative sentiment distribution. This approach operates by targeting specific negative URLs with legal removal requests or diluting their visibility using temporary link-building campaigns. While this offers rapid stabilization during high-intensity news cycles, it introduces substantial risk exposure. Search engine algorithms frequently identify sudden, unnatural patterns in link acquisition or content publication, which can trigger manual reviews or algorithmic suppression of the newly created assets.
The long-term impact on entity credibility favours the proactive model. Proactive networks feed search engine knowledge graphs with structured data, making the overall SERP profile resilient against sudden shifts in media narrative. Reactive methods leave the underlying information architecture fragile, as the entity remains dependent on the continuous suppression of underlying negative assets rather than the cultivation of genuine authority.
What Are the Mechanisms and Structural Limitations of Technical Content Removal?
Technical content removal involves the permanent eradication of a digital asset from either the hosting web server or a search engine’s index. This process utilizes legal frameworks, such as copyright law, defamation claims, or right-to-be-forgotten petitions, alongside technical requests like URL de-indexing via search consoles. The mechanism relies on changing the crawlability or indexing eligibility of a specific URL, forcing the search engine to drop the asset from its index entirely. Once removed, the negative asset ceases to influence the sentiment distribution for that specific query.
The primary limitation of technical removal is its narrow applicability. Legal and technical removals require a clear violation of statutory law or platform terms of service, meaning accurate but highly damaging editorial commentary cannot be removed through these mechanisms. Furthermore, this approach risks triggering the Streisand effect, where the documentation of a removal attempt becomes a fresh, high-authority news item that ranks prominently for the entity’s name. This creates a secondary cycle of negative sentiment distribution that is often harder to suppress than the original asset.
From a scalability perspective, technical removal is highly inefficient for broad-scale reputation repair. It addresses symptoms rather than the systemic search footprint, leaving the politician vulnerable to new content variants published on alternative domains. Relying solely on removal strategies ignores the algorithmic necessity for positive trust signals, resulting in an empty informational space that competing entities can easily exploit.
How Do Automated Sentiment Tracking Tools Evaluate Public Trust?
Automated sentiment tracking tools evaluate public trust by processing natural language data extracted from news sites, forums, and social platforms. These systems employ natural language processing (NLP) algorithms to categorise text into positive, negative, or neutral vectors, calculating an aggregate reputation score for the entity. The mechanism operates by identifying semantic clusters and keyword co-occurrences around a politician’s name, allowing strategists to map shifts in public perception in real time. This data provides the baseline metrics needed to adjust content enhancement campaigns dynamically.
A significant limitation of automated sentiment tracking is its inability to decode complex linguistic nuance, irony, or localized political context accurately. Algorithmic sentiment analysis frequently miscategorises policy debates or sarcastic public commentary, leading to skewed data outputs. If a strategy relies too heavily on these automated metrics, resources may be misallocated toward addressing false-positive sentiment drops while missing deeper, structurally critical shifts in entity credibility.
In the context of search ecosystem influence, sentiment tracking tools show where vulnerabilities exist but do not alter search ranking influence directly. They function strictly as diagnostic mechanisms, mapping the digital landscape without modifying the actual indexation or authority of the documents shaping that landscape.
Why Does Algorithmic Authority Dictate the Sustainability of a Digital Footprint?
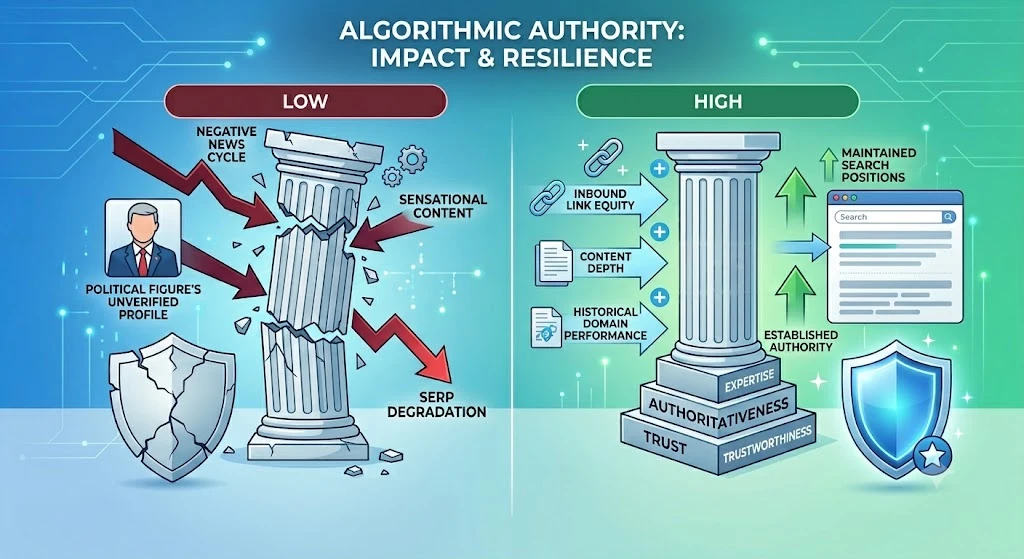
Algorithmic authority is the value a search engine assigns to an entity based on its perceived expertise, authoritativeness, and trustworthiness. Search engines calculate this by analyzing inbound link equity, content depth, and historical domain performance. For political figures, establishing this authority means transforming digital profiles from simple placeholders into definitive information nodes that search engines trust implicitly. The mechanism functions by satisfying core algorithmic quality guidelines, ensuring that official statements and verified policy pages rank above unverified third-party commentary.
Sustainability in reputation management is impossible without high algorithmic authority. When a negative news cycle occurs, domains with established authority maintain their search positions, buffering the candidate’s primary SERP from sudden degradation. Conversely, an entity lacking structural authority will see its search landscape shift rapidly, allowing low-quality, highly sensationalized content to capture top-tier visibility.
Building this authority requires strict adherence to structured data standards, consistent content deployment, and clean digital reference profiles. This structural baseline ensures that the search engine consistently recognises the politician’s owned assets as the most relevant answers for user queries.
What Strategic Considerations Determine the Choice of Reputation Framework?
Selecting an online reputation control method requires a balanced assessment of immediate vulnerability against long-term search ecosystem stability. A comprehensive framework balances content suppression with proactive entity development to ensure resilient search visibility.
To guide the strategic implementation of these methodologies, political entities evaluate options using a systematic four-stage framework:
1.Audit Entity Footprint:Phase 1.
Map the existing sentiment distribution across the top three pages of major search engines to identify high-risk URLs and unverified entity connections.
2.Establish Primary Nodes:Phase 2.
Deploy highly optimised, structured data profiles and verified domains to anchor the knowledge graph and build foundational algorithmic authority.
3.Execute Content Enhancement:Phase 3.
Publish deep, topic-specific resources that address policy positions directly, expanding the network of positive digital assets to displace lower-tier negative links.
4.Deploy Continuous Monitoring:Phase 4.
Track search ranking influence and sentiment shifts using diagnostic tools to counter algorithmic drift and emerging informational threats proactively.
Ultimately, long-term stability depends on shifting from reactive defense to the continuous cultivation of digital authority. While short-term suppression methods stabilize volatile situations, only a sustained, structurally sound content network permanently secures an entity’s digital trust system against shifting public narratives and algorithmic adjustments. Understanding the core drivers of search visibility allows campaigns to maintain an accurate, resilient public record. For those looking at comprehensive long-term positioning strategies, evaluating how clear my name helps politicians build public trust online provides deep insight into modern digital public affairs management.
Frequently Asked Questions
How do search engines evaluate a politician’s online reputation?
Search engines evaluate an entity’s digital profile by analyzing the consistency, authoritativeness, and trustworthiness of information across high-authority web domains. Algorithms map relationships within a knowledge graph, prioritizing authoritative journalistic sources and official digital assets to determine the sentiment distribution for a politician’s name. Systematic search perception analysis helps identify how algorithmic trust factors weigh positive content against unverified third-party claims.
What is the difference between content suppression and content removal for public figures?
Content removal permanently deletes an indexed asset from a server or search engine through legal frameworks like defamation claims or copyright notices. In contrast, content suppression utilizes proactive SEO techniques to promote positive, high-authority digital assets, effectively down-ranking negative links to lower search engine results pages. The specialists at Clear My Name emphasize that while removal eliminates a specific compliance risk, suppression alters the overall sentiment distribution more sustainably.
Can automated sentiment tracking accurately measure voter trust?
Automated sentiment tracking utilizes natural language processing (NLP) to categorize digital public commentary into positive, negative, or neutral vectors. While these tools provide rapid data points regarding algorithmic reputation signals, they often struggle with linguistic nuance, localized political context, and sarcasm. Consequently, digital trust systems must pair automated metrics with qualitative search perception analysis to understand real voter trust accurately.
How does building a semantic content network protect a candidate’s digital footprint?
A semantic content network establishes an interconnected web of verified web assets and structured data profiles that explicitly define a candidate’s policy positions and expertise. This proactive mechanism saturates search engine results pages with controlled, high-authority nodes that are highly resilient against sudden spikes in negative search volume. By feeding the search engine’s knowledge graph consistent entity data, the candidate mitigates the impact of reactive crises.
What are the main risks of relying on reactive crisis management for political SEO?
Reactive crisis management relies on rapid content deployment and short-term link building to suppress sudden negative news cycles, which can trigger manual search reviews due to unnatural footprints. This approach fails to fix underlying entity authority and leaves the primary digital footprint vulnerable to future algorithmic updates. Long-term digital trust requires structural content enhancement rather than continuous, short-term dilution of negative sentiment distribution.