
What Customers Notice First When Researching a Business Online refers to the immediate visual and contextual evaluation a user performs upon encountering an entity’s brand SERP (Search Engine Results Page). Within modern search ecosystems, this initial evaluation relies on aggregated trust indicators, structured data snippets, and prominent sentiment signals that search engine algorithms select and display to satisfy user intent.
What is Search Reputation Management within Modern Search Ecosystems?
Search reputation management defines the systematic process of monitoring, structuring, and optimizing the publicly available digital footprints that determine how an entity is perceived within search engine results. Online reputation refers to the collective synthesis of algorithmically curated data points—ranging from third-party reviews to authoritative media mentions—that form a digital consensus regarding an object or organization. Within a semantic web framework, search engines do not merely index isolated text blocks; they evaluate entities (people, places, concepts, and businesses) and the relationships between them. Consequently, search reputation management functions as an architectural discipline that aligns web content with the specific criteria algorithms use to calculate trust, authority, and credibility.
The underlying mechanism of search reputation relies on entity extraction and sentiment analysis. Search engines crawl digital assets across the web, identifying core nodes of information associated with a brand name. Natural language processing (NLP) models evaluate the context of these mentions, assigning sentiment scores to user-generated content, news articles, and forum discussions. These scores directly influence search visibility. When a search engine detects high concentrations of authoritative, positive sentiment signals, it rewards the entity with enhanced visibility features, such as knowledge panels, rich snippets, and higher organic rankings. Conversely, conflicting data or unaddressed negative signals degrade the entity’s algorithmic trust score, leading to reduced visibility and distorted user perceptions.
How do Search Engines Construct the First Digital Impression of a Business?
Search engines construct the initial digital impression of an entity by compiling diverse data sources into a structured layout known as a brand SERP. When a user executes a navigational query for a specific business, the algorithm prioritizes components that offer the highest informational density and relevance. These components typically include localized map listings, knowledge graphs, aggregated star ratings, and top-ranking organic links. The configuration of these elements dictates exactly what a user notices first, making the brand SERP the primary battleground for entity perception control.
The core mechanism governing this construction is algorithmic curation based on trust signals. Search engines evaluate the freshness, authority, and consistency of data across the web before displaying it prominently. For instance, review schema markup allows algorithms to parse third-party ratings and display them directly on the SERP as rich snippets. This structural display acts as an immediate trust shortcut for users. The presence of a comprehensive, accurate knowledge panel signals to both the user and the algorithm that the entity possesses high topical authority and verified real-world existence, stabilizing its search perception.
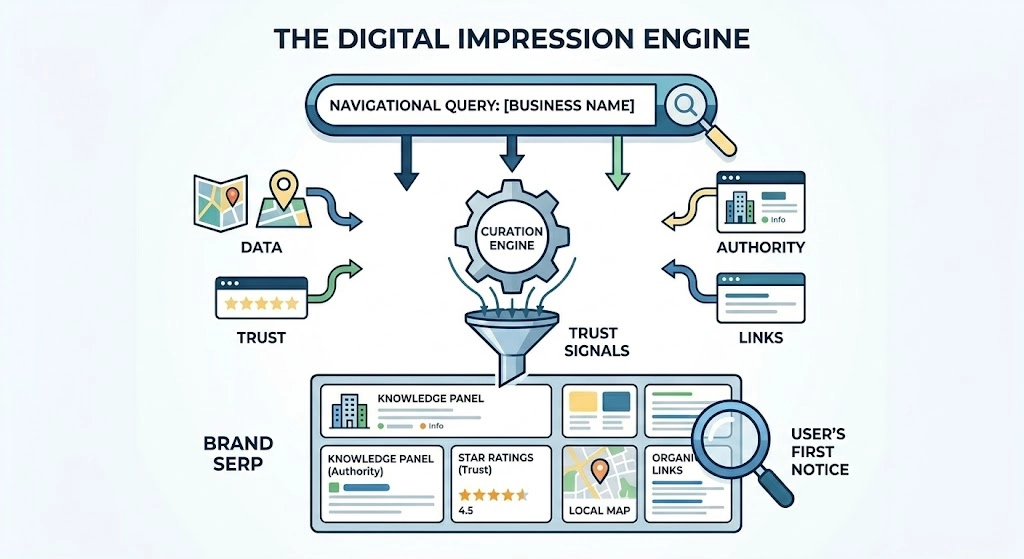
Why do Review Aggregators Control Initial Perceptual Evaluation?
Review aggregators control the initial perceptual evaluation because human cognitive processing prioritizes visual, quantified trust indicators over dense textual data. Within search results, aggregated star ratings and total review counts represent the most visually distinct elements on a page. Search engine algorithms deliberately elevate these data streams because they directly address user risk-mitigation intent. A user analyzing a business relies on these consolidated metrics to make instantaneous binary decisions regarding the credibility of an organization before clicking any organic link.
The impact on search visibility is determined by review velocity, volume, and diversity across independent platforms. Search algorithms utilize these three metrics to assess the ongoing validity of an entity’s reputation.
- Velocity measures the speed and consistency at which new reviews accumulate.
- Volume establishes statistical significance, ensuring the rating is not statistical noise.
- Diversity checks that sentiment signals appear across multiple authoritative domains rather than a single isolated channel.
When these three metrics align, search engines display review snippets with high prominence, driving up click-through rates and reinforcing the entity’s overall search authority.
How do Algorithms Interpret Authority and Trust Signals?
Algorithms interpret authority and trust signals through complex evaluation frameworks designed to measure content quality and source integrity. The most notable framework is Google’s E-E-A-T (Experience, Expertise, Authoritativeness, Trustworthiness) guidelines, which serve as an algorithmic blueprint for evaluating web documents. Trust acts as the central pillar of this system. Search engines evaluate whether the creator of a piece of content has first-hand experience, whether the publishing domain possesses verified expertise, and whether independent, authoritative sources recognize the entity as an industry leader.
This interpretation operates through a network of digital citations, primarily backlinks and unlinked brand mentions. When an authoritative domain links to a business or mentions its name in a positive context, it passes a trust signal through the web graph. Algorithms analyze the semantic context surrounding these citations to confirm that the business is legitimate and reliable. If an entity accumulates citations from suspicious or low-quality sites, the algorithm downgrades its trustworthiness score. This degradation directly suppresses the entity’s organic search visibility, making it difficult for the business to control its perception on the first page of search results.
What Role does Content Indexing Play in Shaping Sentiment?
Content indexing defines the algorithmic ingestion, analysis, and storage of web pages within a search engine’s database, a process that directly dictates which sentiment signals are visible to the public. When a search engine indexes a new document, NLP models parse the text to identify keywords, entities, and emotional modifiers. This analysis calculates the overall sentiment polarity of the document, classifying it as positive, neutral, or negative. The search engine then positions this document within its index based on its perceived relevance and authority relative to specific user queries.
The visibility of specific sentiment signals depends entirely on content ranking dynamics. If negative content—such as an investigative news report or an unresolved regulatory complaint—originates from a domain with high domain authority, search engines index and rank that content above positive assets owned by the business. This occurs because the algorithm prioritizes source authority over brand preference. Consequently, an entity’s search perception is highly vulnerable to the indexing of authoritative third-party content. Managing this risk requires a continuous influx of high-quality, structurally optimized content designed to outrank and displace negative sentiment nodes within the index.
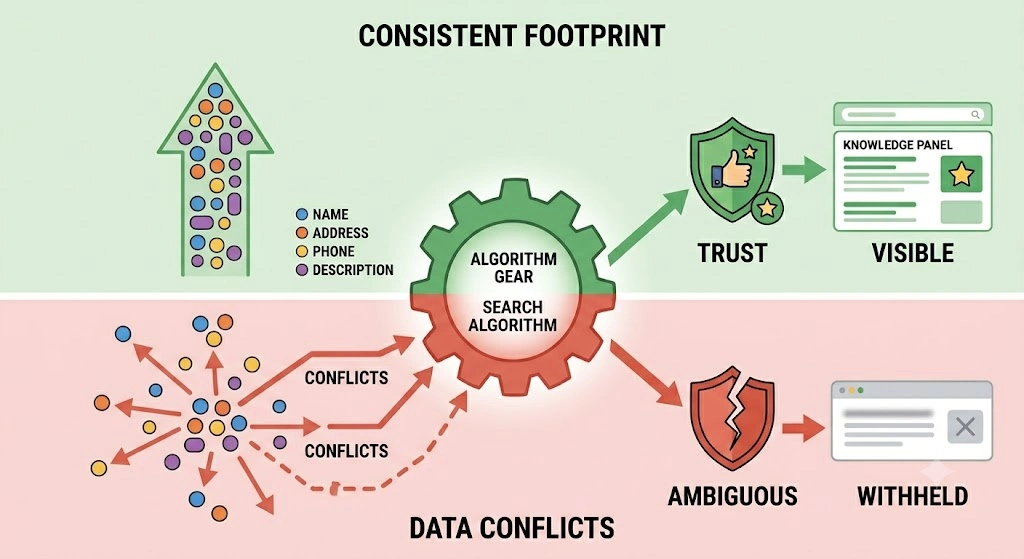
How does Digital Footprint Consistency Influence Algorithmic Trust?
Digital footprint consistency refers to the uniformity of an entity’s core data points across all indexed web environments. Search engines constantly cross-reference data across corporate websites, social media profiles, government registries, and local business directories. The primary data points evaluated include the business name, address, phone number (NAP), and core operational descriptions. When this data matches perfectly across the entire digital ecosystem, search engines validate the entity’s identity, resulting in a higher trust calculation.
Data conflicts introduce algorithmic ambiguity, which directly harms search visibility. If a search engine detects conflicting addresses, outdated business names, or contradictory operational descriptions, it cannot determine which data point is accurate. To protect users from misinformation, the algorithm reduces the visibility of the entity in localized search results and may withhold rich SERP features like knowledge panels. Ensuring complete alignment across every segment of a digital footprint is essential for maintaining the algorithmic trust required to control search perception.
What are the Core Metric Classes Required for Systematic Perception Analysis?
Systematic perception analysis requires the continuous tracking of quantifiable data points that reflect an entity’s health within search ecosystems. Organizations must move away from vague qualitative assessments and instead implement strict data frameworks to evaluate their digital status. These frameworks analyze how efficiently search engines process brand information and how users react to the displayed data.
Understanding the exact data categories that algorithms prioritize allows organizations to pinpoint structural weaknesses in their digital presence. To monitor these dynamics accurately, operators split data collection into distinct categories, as outlined in the following structure.
| Metric Class | Target Indicators | Algorithmic Relevance |
| Visibility Metrics | Share of voice, brand SERP dominance, keyword rankings | Determines the total surface area controlled by the entity in search results. |
| Sentiment Metrics | Review scores, ratio of positive-to-negative URLs, NLP polarity | Controls how search engines calculate the trust and safety scores of an entity. |
| Authority Metrics | Domain authority of ranking URLs, backlink profiles, entity citations | Dictates how resistant the first page of search results is to negative content injections. |
Analyzing these classes provides a granular view of an entity’s search position. By isolating shifts within these specific categories, businesses can identify whether a drop in visibility stems from technical indexing issues or a systemic decline in algorithmic trust caused by negative external signals. This data-driven approach forms the foundation for objective perception control.
Controlling what customers notice first when researching a business online requires a deep understanding of semantic search mechanics, entity extraction, and algorithmic trust frameworks. Search engines construct digital impressions by compiling aggregated review data, structural schemas, and authoritative content into a highly visible brand SERP. Every element displayed is a direct reflection of how algorithms interpret the authority, trustworthiness, and consistency of an entity’s digital footprint. By systematically analyzing these search signals and optimizing web assets to align with E-E-A-T criteria, organizations can stabilize their search visibility and ensure that algorithms present a credible, trustworthy representation of their entity to users executing navigational queries. Tracking these shifts effectively requires a mastery of the most important KPIs for reputation monitoring to ensure long-term digital stability.
Frequently Asked Questions
How do search engine results affect a business reputation?
Search engine results dictate digital perception by serving as the primary source of verified information for users evaluating an organization. Algorithms aggregate structured data, review snippets, and authoritative media links to construct a brand profile that directly influences consumer trust. If negative sentiment nodes or unverified information dominate the first page, an entity’s overall search visibility and credibility drop significantly.
What do customers check first when looking up a business online?
Customers prioritize quantified, visual trust indicators such as aggregated star ratings, total review volume, and the completeness of an entity’s knowledge panel. These prominent signals serve as a cognitive shortcut, allowing users to evaluate a company’s real-world reliability before reading individual articles. Organizations utilizing professional reputation management for business focus heavily on stabilizing these immediate digital touchpoints to minimize user risk perception.
How can a company fix inaccurate search results on its brand page?
Rectifying inaccurate search results requires a systematic approach to content indexing, data consistency, and entity authority. Clear My Name addresses these distortions by deploying highly optimized, authoritative digital assets designed to outrank and displace negative or incorrect sentiment signals. This alignment of the brand’s digital footprint ensures that search engine algorithms ingest, validate, and display accurate information to the public.
Why do third-party review sites rank so high in search ecosystems?
Search engine algorithms prioritize independent third-party platforms because they possess high domain authority and directly satisfy user intent for objective verification. These platforms utilize structured review schema that algorithms easily parse, extract, and display as rich snippets on the main results page. Consequently, maintaining positive sentiment and consistent velocity across these external channels is critical for controlling entity perception.
How do search algorithms evaluate the credibility of an online profile?
Algorithms assess credibility by measuring digital footprint consistency and evaluating trust signals against established E-E-A-T (Experience, Expertise, Authoritativeness, Trustworthiness) frameworks. The system cross-references core entity data across directories, registries, and citations while scanning surrounding text via natural language processing models to calculate a total sentiment score. A high concentration of aligned, authoritative citations signals legitimacy, which stabilizes search visibility.